Let’s Stop Treating Algorithms Like They’re All Created Equal

All around us, algorithms are invisibly at work. They’re recommending music and surfacing news, finding cancerous tumors, and making self-driving cars a reality. But do people trust them?
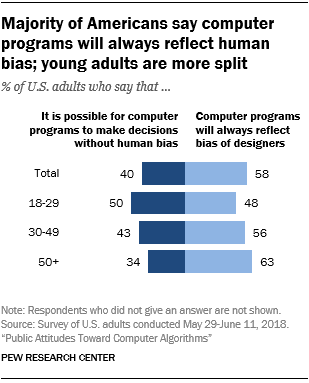
Not really, according to a Pew Research Center survey taken last year. When asked whether computer programs will always reflect the biases of their designers, 58 percent of respondents thought they would. This finding illustrates a serious tension between computing technology, whose influence on people’s lives is only expected to grow, and the people affected by it.

The lack of trust in any particular technology impedes its acceptance and use. On one hand, justified distrust of dangerous technology is a good thing. Nobody objects to eliminating the use of bad algorithms that have undesirable consequences, such as the Therac-25 software that delivered radiation overdoses to patients or the incorrect unit computation that caused NASA to lose its Mars Climate Orbiter. On the other hand, people’s irrational fear of safe technology, such as vaccination, can itself be dangerous. It is not only that those who distrust technology will personally miss out on the benefits, but their refusal to participate can negatively affect other people and have an overall detrimental effect on society.
It is important to distinguish between rational and irrational fears, and to not contribute to the latter, particularly if you’re in the position to influence public opinion.
It is therefore important to distinguish between rational and irrational fears, and to not contribute to the latter, particularly if you’re in the position to influence public opinion. Unfortunately, this particular Pew poll, or at least the way the results were reported, has muddied the waters. The survey asked respondents about four different scenarios in which algorithms were making decisions: computing a personal finance score, assessing criminal risk for making parole decisions, screening resumes of job applicants, and analyzing job interviews. The headline of the lead graphic sums up its findings: “Majority of Americans say computer programs will always reflect human bias; young adults are more split.”
The problem with that statement is that it incorrectly equates the general notion of an algorithm with that of a particular kind of algorithm. The algorithms that are used in the presented scenarios are machine-learned, which means they are essentially black boxes that represent their logic internally as a collection of numbers that have no apparent meaning. A problem with these machine-learned algorithms is that they are effectively unreadable and cannot be understood by humans.
In contrast, human-created algorithms are readable; they are given in a language that can be understood by other humans. This includes descriptions given in natural languages (recipes, driving instructions, rules for playing a game, instructions to assemble furniture, etc.) as well as programs written in programming languages that can be executed by machines.
The difference in terms of readability and understandability between these two kinds of algorithms is crucial for judging the trustworthiness of algorithms. It’s not that human-created algorithms are always correct. Quite the opposite is true: Since humans are fallible, so are their products, and algorithms and software in general is notorious for containing bugs. But a crucial difference between readable and unreadable algorithms is that the former can effectively be corrected while this is not possible for the latter.
If a dish is too salty, you can find the place in the recipe where salt is added and reduce the amount, or when driving instructions lead you to the wrong place, it is easy to identify the incorrect turn and fix the mistake. The situation is quite different for unreadable algorithms. When we observe an incorrect behavior, we cannot identify a specific place in the algorithm description that is responsible for it and could be fixed. The black-box nature of machine-learned algorithms effectively prevents this. The only way to change the faulty behavior of a machine-learned algorithm is to retrain it with new data, which might then introduce other biases.
Bias in data is a legitimate concern for algorithms, but only for algorithms whose decisions are based on bad data. In talking about algorithms, in particular when assigning blame and raising alarm bells, we should be careful to distinguish between readable and unreadable (that is, machine-learned) algorithms.
Bias in data is a legitimate concern for algorithms, but only for algorithms whose decisions are based on bad data.
Coming back to the Pew Research poll, we can notice that it too is, in fact, an algorithm, one that is run with different people’s answers as input. To be clear, there is no issue with the methodology employed, and the scenarios that people were asked about are important, but the way the results were reported is misleading and arguably irresponsible. Ironically, it is biased in its selection of example scenarios, and thus it’s an example of the very phenomenon it decries. Fortunately, since the Pew poll was created by humans, we can identify the flaws and correct it. An easy fix is to simply change the headline and report that people don’t trust machine-learned algorithms. Another possibility is to present a number of non-machine-learned algorithm examples and incorporate the people’s responses to those in the survey as well.
To get a more accurate sense of people’s attitudes towards algorithms, and also to avoid creating unnecessary aversions and false panics, anyone judging algorithms should distinguish between those created by humans and those that are the result of machine learning. Pollsters, journalists, and everybody else involved in gauging, and influencing, public opinion would benefit from a better understanding of the nature of algorithms. As would the people being polled.
It is true that algorithms can be flawed, but so can opinion polls. Let’s try to avoid bias in both.
Martin Erwig is the Stretch Professor of Computer Science at Oregon State University and the author of “Once Upon an Algorithm: How Stories Explain Computing.“